



Онлайн-гарантии сейчас выдаются только в секторе государственного заказа. Система госзакупок прозрачная и открытая. Информация об участниках тендеров является публичной, что дает банку возможность из открытого источника получить информацию о поставщике по контракту, об опыте его участия в подобных госзаказах, качестве их исполнения и, имея эти сведения, быстро провести нужную оценку [1].
Однако, несмотря на то что портал Единой информационной системы (ЕИС) в сфере закупок по своей сути представляет собой огромную открытую базу данных, она недостаточно проста в использовании и навигации. Поиск данных на портале имеет ограничения, связанные с количеством строк для выгрузки csv-файлов. Кроме этого, для сбора комплексной информации о контракте необходимо переключаться по нескольким вкладкам внутри страницы с карточкой контракта, что неудобно ни для ручной сборки данных, ни для написания алгоритма парсинга сайта.
Путем к решению проблемы трудоемкого извлечения данных с официального сайта Единой информационной системы служит FTP-сервер портала системы. На FTP-сервере содержится структурированная версия данных сайта в виде архивируемых файлов формата XML (текстовые файлы, которые используют пользовательские теги для описания структуры документа). Сведения на FTP-сервере содержат полную региональную выгрузку информации, опубликованной на официальном сайте ЕИС. В полную региональную выгрузку включаются сведения о контракте и его изменении, а также информация об исполнении / прекращении действия контракта.
Конкретный адрес FTP-сервера зависит от Федерального закона, согласно которому осуществляются закупки. Для 44-ФЗ адресом FTP-сервера является строка ftp://zakupki.gov.ru (логин и пароль: free).
Согласно официальной документации ЕИС [2], каждый календарный день на FTP-сервер выгружаются действующие редакции документов, опубликованные за предыдущий календарный день (от 00:00:00 до 24:00:00 предыдущего календарного дня до момента выполнения выгрузки). Также каждый календарный месяц выгружаются действующие редакции документов, опубликованные за предыдущий календарный месяц.
В ежедневной и ежемесячной выгрузках всегда присутствуют все типы документов, опубликованных за прошедший календарный день или календарный месяц соответственно. Если на момент формирования выгрузки за истекший период не было ни одного опубликованного документа какого-нибудь типа, то XML-файл с данным типом документов выгружается пустым.
Таким образом, производя загрузку данных ежедневной или ежемесячной выгрузки данных в зависимости от нужд организации с FTP-сервера в контур банка, можно получать актуальные данные по контрактной базе.
В литературе [3; 4] было обнаружено описание создания моделей, способных прогнозировать результат исполнения контракта на основе данных Единой информационной системы в сфере закупок. Однако цели разработки этих моделей не касались банковского сектора, а инструменты парсинга данных из ЕИС описаны не были. Кроме этого, в открытых источниках информации не было найдено сведений о том, какие методы моделирования и технологии сбора данных для построения своих моделей используют банки для автоматизации процесса принятия решения по выдаче банковской гарантии.
Таким образом, научная новизна и цель работы заключаются в:
– разработке автоматизированного способа получения комплексной информации о заключенных контрактах (на примере контрактов по 44-ФЗ) при помощи технологий парсинга XML-файлов, расположенных на FTP-сервере ЕИС, с использованием библиотеки lxml языка Python;
– обоснованном выборе наиболее применимого метода машинного обучения для применения в задаче прогнозирования результата исполнения госконтракта, решаемой для обеспечения поддержки принятия решения по выдаче банковской гарантии.
Материал и методы исследования
Для получения исторических данных о контрактах конкретного региона в виде csv-файлов, пригодных для автоматизированной обработки, необходимо произвести следующие действия:
1) извлечь архивы из каталога contracts, лежащего внутри каталога соответствующего региона на FTP-сервере;
2) распарсить XML-файлы в соответствии с их структурой из собранных архивов при помощи библиотеки lxml;
3) сохранить распарсенные данные XML-файлов в csv-файлы с разделителем ‘\t’ (применение этого разделителя более надежно, чем применение классической запятой).
Для реализации второго и третьего шага были более подробно изучены документы, которые помещаются внутрь каталога contracts. Из подкаталога contracts для работы интерес представляют следующие два типа документов: информация о заключенном контракте (его изменении) и информация об исполнении (исполнение обязательств по предоставленной гарантии качества, расторжение, возврат переплаты по контракту, признание контракта недействительным) контракта.
В результате отработки скрипта парсинга было сформировано четыре csv-файла, которые включили в себя 556 314, 571 878, 791 953 и 2 119 707 строк соответственно.
Данные по контракту с течением времени могут изменяться. При их корректировке на FTP-сервере ЕИС госзакупок публикуются обновленные XML-файлы с информацией по контракту, при этом исторически загруженные XML-файлы также на FTP-сервере сохраняются. В результате такого дублирования публикаций сведений о контракте в распарсенных csv-файлах возникли случаи появления нескольких строк с данными, выгруженными на FTP-сервер в разное время, на один номер контракта.
Во избежание переобучения модели прогнозирования результата исполнения контракта на задвоенных исходных данных по контракту, приведенное дублирование информации по одному контракту было устранено путем отбора последних актуальных данных, выгруженных на FTP-сервер ЕИС.
Далее все четыре предобработанных csv-файла были соединены в одну таблицу при помощи объединения по номеру контракта, присутствующему в каждой таблице. В таблицу с результатом объединения был добавлен еще один признак, характеризующий контракт – признак того, что регионы поставщика и заказчика совпадают (sup_cust_same_reg), который был заполнен значением 1, если первые две цифры в ИНН поставщика и заказчика совпали, в противном случае было проставлено значение 0.
Также в результирующей таблице был сформирован целевой признак, обозначающий результат исполнения контракта (termination_result), который был рассчитан на основе поля termination_date: если дата расторжения контракта была указана, то контракт принимался расторгнутым и в поле termination_result проставлялось значение 1, иначе termination_result заполнялся значением 0.
На основе полученной таблицы были собраны и дополнительно добавлены в выборку четыре агрегата, характеризующие историю исполнения контрактов поставщиком.
Этими агрегатами стали количество исполненных контрактов поставщиком за последние 90 дней до даты заключения рассматриваемого контракта (cnt_end_90), сумма исполненных контрактов поставщиком за последние 90 дней до даты заключения рассматриваемого контракта (sum_end_90), количество и сумма новых контрактов, заключенных поставщиком за аналогичный период (cnt_new_90 и sum_new_90 соответственно).
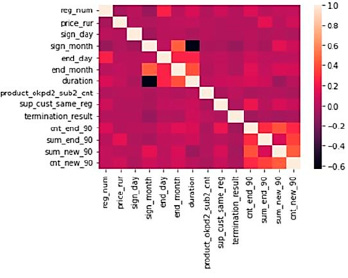
Рис. 1. Корреляционная матрица признаков
После составления итоговой выборки признаки в ней были проверены на корреляцию. Степень корреляции между атрибутами приведена на рисунке 1, сделанном при помощи библиотеки seaborn.
Выяснилось, что месяц даты заключения контракта сильно коррелирует с его длительностью, поэтому признак sign_month был исключен из дальнейшего рассмотрения. В результате размер выборки для моделирования сократился до 153 108 строк, уникальным идентификатором для которых является пара значений номера контракта и ИНН поставщика. Количество записей с расторгнутыми контрактами составило 9 901. На вход моделям машинного обучения будет подаваться 92 признака-предиктора и 1 целевой признак.
Для модели прогнозирования результата исполнения контракта в сфере госзакупок пригодны такие методы машинного обучения, как логистическая регрессия, дерево решений и случайный лес, поскольку эти методы хорошо интерпретируемы.
Модель логистической регрессии (логит-модель) относится к классу моделей бинарного выбора, в которых выходная переменная принимает только два возможных значения: y ∈ {0,1}. Вероятность наступления события, при котором y = 1, рассчитывается с помощью логистической функции, график которой приведен на рисунке 2:
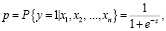 (1)
(1)
где р – вероятность наступления события, при котором y = 1 (принимает значения от 0 до 1), 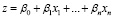 – интегральный показатель (принимает значения от –∞ до +∞), xi – предикторы модели, βi – параметры, которые требуется оценить, i = 1, …, n [5].
– интегральный показатель (принимает значения от –∞ до +∞), xi – предикторы модели, βi – параметры, которые требуется оценить, i = 1, …, n [5].
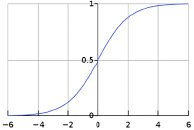
Рис. 2. График логистической функции
Для определения значения бинарной переменной y применяют порог отсечения. При значении p меньше выбранного порога прогнозируемое значение выходной переменной считается равным нулю, в противном случае – равным единице. Обычно, если отсутствуют априорные предположения о данных, пороговое значение принимают равным 0,5 [5].
Алгоритм CART (Classification And Regression Tree) – алгоритм построения бинарного дерева решений. В этом алгоритме каждый узел дерева имеет только двух потомков. На каждом шаге построения дерева формируемое в узле правило делит обучающую выборку на две части: часть, в которой правило выполняется, и часть, в которой оно не выполняется [6].
Библиотека scikit-learn для языка Python использует оптимизированную версию алгоритма CART. Визуализация работы этого алгоритма представлена на рисунке 3.
В процессе обучения дерева узлами дерева становятся наиболее информативные предикаты. Существует формула оценки информативности условия, размещенного в вершине дерева:
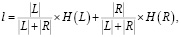 (2)
(2)
где L и R – множества примеров, попадающих в результате разбиения по условию в левый и правый узлы дерева соответственно.
Оценка же качества разбиения дерева производится по функциям H(L) и H(R), которые оцениваются с помощью индекса Джини, энтропии Шеннона или ошибки классификации.
Индекс Джини вычисляется по формуле
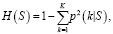 (3)
(3)
где p(k|S) – доля экземпляров класса k в S, k – количество классов, S – некоторое множество обучающих объектов.
Энтропия Шеннона рассчитывается по формуле
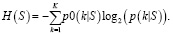 (4)
(4)
Ошибка классификации находится по формуле
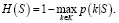 (5)
(5)
Случайные леса состоят из определенного пользователем числа деревьев решений, которые строятся с помощью модифицированного алгоритма CART.
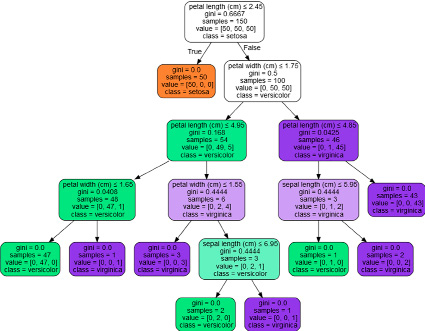
Рис. 3. Алгоритм CART
В алгоритме использованы два подхода: 1) каждое дерево обучается на собственной подвыборке исходных данных (bootstrapped data); 2) при построении деревьев решений используются различные подмножества факторов. То есть сначала строятся деревья решений, которые затем «голосуют» за принадлежность объекта к определенному классу [7–9].
Осуществим прогнозирование результата исполнения контракта в сфере госзакупок тремя представленными выше методами машинного обучения, а также определим наиболее эффективный метод машинного обучения для прогнозирования.
Результаты исследования и их обсуждение
Полученный набор данных о контрактах был разделен на две части: обучающую и тестовую выборки. В обучающую выборку попало 77% данных, в тестовую – 33%. Поскольку контракты с меткой 1 (расторгнутые) составляют всего 6,5% от общего объема, при разделении выборки на обучающую и тестовую была применена опция stratify модуля train_test_split [10] библиотеки scikit-learn. При использовании этой опции разделение производится таким образом, что внутри обучающей и тестовой выборок сохраняется соотношение классов.
После того как выборка для обучения моделей была сформирована, на ее основе было обучено три классификатора, также входящие в библиотеку scikit-learn: LogisticRegression, DecisionTreeClassifier и RandomForestClassifier.
Для улучшения качества работы обученных методов, с помощью модуля GridSearchCV на обучающей выборке были подобраны параметры, с которыми каждый из методов показал более высокое значение метрики качества. За основу метрики качества была взята метрика ROC-AUC. Определение лучшего набора параметров производилось при помощи 5-кратной кросс-валидации.
Визуализация работы кросс-валидации приведена на рисунке 4.
Значение метрики качества работы модели, найденное на кросс-валидации, представляет собой среднее значение вычисленных в цикле значений метрики на каждой из k итераций.
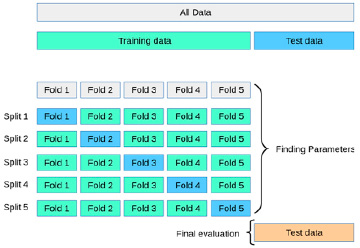
Рис. 4. Кросс-валидация
GridSearchCV принимает на вход модель и различные значения ее параметров для подбора (сетку параметров). Модуль осуществляет так называемый поиск по сетке: для каждого возможного сочетания значений параметров рассчитывается метрика качества, в конце выбирается такое сочетание параметров, при котором метрика качества получает наибольшее значение (или наименьшую ошибку, если она задана).
Для модели логистической регрессии при помощи поиска по сетке подбирались параметры C (обратный коэффициент регуляризации) и solver (алгоритм выбора параметров оптимизации, который определяет метод оптимизации для функции потерь логистической регрессии). Для дерева решений – criterion (критерий измерения качества разделения дерева) и max_depth (максимальная глубина дерева). Для случайного леса – n_estimators (количество деревьев в лесу), criterion (критерий измерения качества разделения дерева) и max_depth (максимальная глубина дерева).
В результате лучшими параметрами для логистической регрессии оказались C=0,001; solver=’liblinear’. Для дерева решений – criterion=’entropy’; max_depth=10. Для случайного леса – criterion=’entropy’; max_depth=20; n_estimators=200.
На практике метрика ROC-AUC была вычислена для каждого из трех классификаторов на тестовой выборке данных после подбора их параметров при помощи модуля roc_auc_score библиотеки scikit-learn.
Классификаторы показали следующие результаты: для логистической регрессии площадь под кривой ошибок составила 0,48; для дерева решений – 0,73; для случайного леса – 0,80.
Визуализация кривой ошибок для случайного леса приведена на рисунке 5.
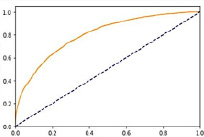
Рис. 5. Кривая ROC-AUC (ось x – False Positive Rate, ось y – True Positive Rate)
Итак, наиболее качественной моделью признается классификатор случайного леса, потому что имеет максимальное значение метрики ROC-AUC среди полученных значений.
Заключение
По итогам проделанной работы можно заключить, что разработанная автоматизированная система на базе методов машинного обучения и парсинга данных сможет эффективно осуществлять прогнозирование исполнения госконтракта.
Увеличившаяся скорость принятия решения позволит банку удовлетворить потребности своих клиентов в скорости предоставления услуги, стать более привлекательным для них, тем самым сохранить или приумножить свою прибыль.
При этом процесс выдачи банковских гарантий в ускоренном режиме наиболее актуален для применения на большом количестве отдельных гарантий на небольшие суммы, поэтому такой подход имеет смысл применять для сегмента малого и среднего бизнеса.