



Сегодня в мире цифровых технологий общество все чаще использует новые каналы связи для коммуникации. В последнее десятилетие активной средой для обмена информацией являются социальные сети («Вконтакте», «Одноклассники» и др.), в которых люди разных возрастных и социальных категорий делятся своими взглядами, эмоциями и жизненными ситуациями. С помощью данных сетей ежедневно генерируется огромный объем гетерогенной информации, анализ которой может быть полезен для прогнозирования общественных волнений, социальной нестабильности, происшествий различного характера и т.д. При наступлении каких-либо происшествий или чрезвычайных ситуаций (далее – ЧС) многие пользователи социальных сетей делятся текстовыми, фото- или видеоматериалами с другими пользователями, формируя тем самым огромный массив информации, которая потенциально может быть использована спасательными службами, позволяя им снизить степень информационной неопределенности и помочь в принятии адекватных управленческих решений при реагировании [1, 2].
В настоящей статье сделана попытка применения новостных данных из социальных сетей для снижения информационной неопределенности, своевременного реагирования на ЧС и проведения превентивных мероприятий с целью минимизации рисков [3], предотвращения возникновения паники и недопущения ухудшения сложившейся ситуации.
Материалы и методы исследования
В целом анализ социальных сетей может быть использован для исследования информационного взаимодействия как отдельных агентов, так и определенных сообществ, образованных в той или иной социальной сети, прогнозирования их поведения, моделирования динамики распространения информации [4].
Ранее многие исследователи в различных научных областях уже проводили анализ социальных сетей. Для получения данных применялись различные подходы. Например, иностранными исследователями широко использовалась классическая модель Кермака – Маккендрика SIR, которая до этого применялась для анализа динамики распространения эпидемий [5], распределенные системы [6], линейные модели влияния [7], эвристико-жадный алгоритм [8], анализ отдельных пользователей [9]. Среди отечественных ученых значительный вклад в развитие теории анализа социальных сетей внесла научная школа Института проблем управления им. В.А. Трапезникова РАН [10]. Кроме того некоторые исследователи в решении данной задачи использовали аппарат теории нечетких множеств и нечеткого когнитивного моделирования [11], клеточные автоматы [12–14], методы имитационного моделирования [15], экспертно-стохастическое моделирование для измерения влияния в социальных сетях [16, 17], цепи Маркова [18] и др.
При использовании данных подходов и адаптации их к реальному миру у исследователей возник ряд вопросов, связанных с многокритериальностью распространения информации в реальном мире; сложностью масштабирования подходов; отсутствием учета взаимоотношений между пользователями в процессе распространения данных о ЧС в социальных сетях.
В статье предлагается новая методика, позволяющая анализировать социальные сети с целью своевременного реагирования на происшествия, а также предотвращения распространения ложной информации. В отличие от существующего подхода к анализу конкретных пользователей социальных сетей [9], в настоящей работе предлагается анализировать также и сообщества, которые объединяют определенное количество пользователей разных социальных групп и взглядов. Это сделано по причине того, что в настоящее время социальными сетями пользуется огромное количество людей, и анализ каждого из них, в свою очередь, будет требовать значительных вычислительных мощностей и ресурсов операторов на обработку результатов. Также анализировать и полагаться на мнения отдельных пользователей имеет смысл только в тех случаях, когда они владеют достоверной информацией и имеют значительное влияние на общество. Целесообразнее анализировать сообщества, охватывающие не только широкие массы людей и имеющие соответствующую тематику направленности, но и генерирующие достаточно большое количество данных. Другими словами, в статье предлагается учитывать также поступающие от групп и сообществ данные. При необходимости более низкоуровневого анализа и детализации возможен переход на учет показателей отдельных пользователей.
В наши дни в России широко распространена социальная сеть «Вконтакте», в которой, по последним данным, зарегистрировано порядка 72,5 млн пользователей. Около половины из них ведут активную деятельность в сети, объединяясь в различные группы и сообщества. В результате поиска по группам тематики экстренных сообщений на территории Санкт-Петербурга и Ленинградской области было найдено порядка пятидесяти сообществ с количеством подписчиков от тысячи до полутора миллионов. Так, сообщество «ДТП и ЧП | Санкт-Петербург | Питер Онлайн | СПб» имеет 1 346 038 подписчиков, «ДТП и ЧП | Ленинградская область Он-Лайн | СПб» – 104 637 подписчиков, «ДТП и ЧП Санкт-Петербурга | Новости | Угоны» – 54 222 подписчика и т.д. Ежедневно в каждом из данных сообществ публикуется порядка 10–40 сообщений о происшествиях, таким образом, общее количество сообщений в сообществах может доходить до нескольких тысяч за сутки. Ручная проверка, анализ и реагирование на данные сообщения экстренными службами в настоящее время практически невозможны по двум основным причинам: отсутствие достаточного количества специалистов и отсутствие специального программного продукта, позволяющего автоматически выявлять достоверные сообщения, обобщать, ранжировать и предоставлять оператору результаты вычислений [19, 20]. Данные причины являются взаимоисключающими: имея специализированное программное обеспечение, необязательно содержать внушительный штат сотрудников, а можно обойтись существующей в настоящее время дежурной сменой. Таким образом, разработка в будущем специализированного программного продукта (далее – ПП) на основе представленной в настоящей статье методики является перспективным направлением для работы. Данный ПП позволил бы решать следующие задачи:
– мгновенный сбор и обобщение информации о происшествиях в режиме реального времени;
– проверка достоверности информации за счет представленного ниже механизма;
– сокращение времени реагирования на происшествия экстренными службами;
– предотвращение распространения ложной информации, пресечение паники населения;
– выявление пользователей, умышленно способствующих распространению ложной информации [21];
– координация сил и средств для реагирования на происшествия и т.д.
Результаты исследования и их обсуждение
Перейдем к описанию предлагаемой методики. Примем следующие условные обозначения: Ri – репутация пользователя Ai, которая отражает доверие других пользователей к мнению, выраженному этим пользователем. Если Ri = 0, другие пользователи не доверяют пользователю Ai, напротив, если 0 < Ri < 1, то другие пользователи доверяют субъективным суждениям пользователя Ai относительно поступающих от него сообщений. Если Ri = 1, другие пользователи полностью доверяют мнению пользователя Ai. Обозначим уровень интереса других пользователей к сообщениям пользователя Ai через Ii с аналогичным характером его оценки. Так, при Ii = 0 другим пользователям не интересны публикации анализируемого пользователя, при 0 < Ii < 1 другие пользователи проявляют некоторый интерес к опубликованным суждениям, при Ii = 1 – проявляют максимальную заинтересованность.
Характер распространения информации о ЧС в социальной сети зависит от параметров определенного пользователя. При составлении шаблонов поведений можно использовать следующие составляющие:
– скорость прочтения и обработки информации (количество постов, прочитанных за единицу времени):
Vr = (Qs / Tr)×Kk , (1)
где Qs – число знаков в тексте (объем); Tr – время, затраченное на чтение текста (в минутах); Kk – коэффициент понимания;
– количество полученных откликов в виде оценок (в частности, в сети «Вконтакте» можно подсчитать количество отметок «нравится», полученных определенным пользователем за публикации):
Lk = Ml / Ts , (2)
где Ml – количество отметок «нравится», полученных определенным пользователем; Ts – время пользовательской сессии;
– количество поставленных откликов в виде оценок определенного пользователя другим пользователям:
Lks = Klks / Ts , (3)
где Klks – количество отметок «нравится», поставленных определенным пользователем за все время существования аккаунта; Ts – время пользовательской сессии;
– публикационная активность характеризуется количеством оставленных постов определенным пользователем:
Ps = Kps / Ts , (4)
где Kps – количество оставленных постов определенным пользователем; Ts – время пользовательской сессии;
– активность распространения характеризуется количеством вторичных публикаций, сделанных определенным пользователем:
Rps = Krs / Ts , (5)
где Krs – количеством вторичных публикаций, сделанных определенным пользователем; Ts – время пользовательской сессии;
– степень одобрения характеризуется количеством положительных комментариев, оставленных под записью определенного пользователя:
Kp = Kpt / Ts , (6)
где Kpt – количество положительных комментариев, оставленных под записью определенного пользователя; Ts – время пользовательской сессии;
– авторитетность пользователя характеризуется количеством активных подписчиков у определенного пользователя:
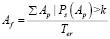 , (7)
, (7)
где Ap – активный пользователь; Ps – публикационная активность; Ter– временной интервал (неделя, месяц, год – зависит от целей исследования); k – коэффициент, определяющий нижнюю границу понятия «активный пользователь» в используемом контексте;
– обратная активность распространения характеризуется количеством вторичных публикаций определенного автора другими пользователями:
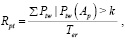 (8)
(8)
где Ap – активный пользователь; Ptw – количество вторичных публикаций; Ter – временной интервал (неделя, месяц, год – зависит от целей исследования); k – коэффициент, определяющий нижнюю границу понятия «активный пользователь» в используемом контексте.
Значения показателей пользователей: личные познания Ci, интересность Ii и репутация Ri – определяются следующим образом:
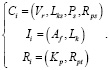 (9)
(9)
Нормализация уровня интереса к пользователю, его репутации и осведомленности вычисляется с помощью следующего выражения:
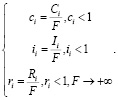 (10)
(10)
Цель пользователя, предоставляющего информацию, заключается в максимизации своей полезности ui в социальной сети, которая определяется как комбинация личных познаний Ci, интересности Ii и репутации Ri:
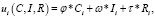
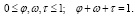 (11)
(11)
Набор весовых коэффициентов φ, ω, τ предназначен для идентификации конкретного типа личности пользователя, а также возможна корректировка в соответствии с приоритетами вычислений, когда, например, необходимо подчеркнуть значимость для исследования одного из параметров.
Относительно составления шаблонов сообществ можно выделить следующие показатели:
– количество активных пользователей (пользователи, оставляющие комментарии к постам, отметки «нравится», делающие вторичные публикации):
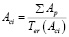 ; (12)
; (12)
– количество постов в сутки на стене сообщества:
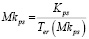 ; (13)
; (13)
– среднее количество просмотров одного поста:
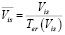 ; (14)
; (14)
– среднее количество комментариев, оставленных к одному посту:
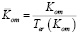 ; (15)
; (15)
– среднее количество вторичных публикаций анализируемого сообщества в других сообществах:
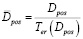 ; (16)
; (16)
– среднее количество отметок «нравится» в других сообществах записи, изначально опубликованной в анализируемом сообществе и вторично опубликованном в других:
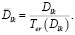 (17)
(17)
Количество данных параметров может быть увеличено в зависимости от целей исследования и функциональных возможностей социальной сети.
С помощью представленных выше параметров можно выразить актуальность Ср, интересность Iр и репутацию Rр сообществ в следующем виде:
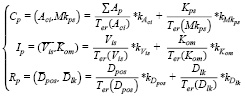 . (18)
. (18)
Нормализация уровня интереса к сообществу, его репутации и актуальности вычисляется с помощью следующего выражения:
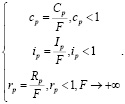 (19)
(19)
Так же как и для отдельных пользователей, цель сообщества состоит в максимизации своей полезности up в социальной сети, которая представляется в виде аддитивной свертки трех показателей (актуальности Ср, интересности Iр и репутации Rр ):
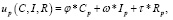
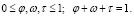 (20)
(20)
Рассмотренные показатели напрямую влияют на оценку достоверности публикуемой информации в анализируемом сообществе, так как из-за имеющейся конкуренции администраторы данных групп стремятся получить как можно большую аудиторию с помощью качественных и интересных материалов, обладающих определенной ценностью. Это позволяет привлекать в сообщество больше людей и подниматься в рейтинге, становясь более популярным. Чем выше рейтинг сообщества, тем большая активность предоставления и передачи информации в нем присутствует.
В свою очередь пользователи, находящиеся в данном сообществе по личным или иным целям, осуществляют некоторую деятельность, которая влияет на все сообщество в целом. Предположим, что в определенном сообществе состоят два пользователя, целью которых, является максимизация ожидаемой полезности. Их отношения между собой рассмотрим в виде стохастической игры с общей суммой:
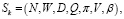 (21)
(21)
где 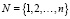 – множество пользователей; W – набор характеристик пользователей;
– множество пользователей; W – набор характеристик пользователей; 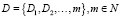 – множество наборов доступных действий пользователя N; Q – функция перехода
– множество наборов доступных действий пользователя N; Q – функция перехода 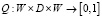 ; π – стратегия пользователей, демонстрирующая вероятность выбора конкретного перехода
; π – стратегия пользователей, демонстрирующая вероятность выбора конкретного перехода 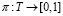 ;
; 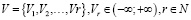 – функция вознаграждения для пользователей, осуществляющих переход по ссылке;
– функция вознаграждения для пользователей, осуществляющих переход по ссылке; 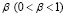 – коэффициент дисконтирования будущего вознаграждения.
– коэффициент дисконтирования будущего вознаграждения.
Допустим, что пользователь i и пользователь j являются соседями в социальной сети, и их игра ведется следующим образом. В момент времени t пользователь i принимает действие 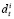 из множества Di, а пользователь j принимает действие
из множества Di, а пользователь j принимает действие 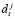 из множества Dj в состоянии wt. Пользователь i получает вознаграждение
из множества Dj в состоянии wt. Пользователь i получает вознаграждение 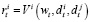 , а пользователь j получает вознаграждение
, а пользователь j получает вознаграждение 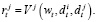 Затем игра переходит в новое состояние wt+1 с условной вероятностью:
Затем игра переходит в новое состояние wt+1 с условной вероятностью:
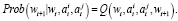 (22)
(22)
Ожидаемое вознаграждение определим как вектор:
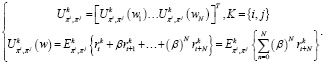 (23)
(23)
Оператор ожидания 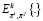 характеризует выполнение действия пользователя k, используя распределение вероятностей πk(wt+n) в wt+n, после чего он получает вознаграждение:
характеризует выполнение действия пользователя k, используя распределение вероятностей πk(wt+n) в wt+n, после чего он получает вознаграждение:
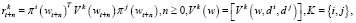 (24)
(24)
где K = {i, j} – матрица вознаграждения пользователя в состоянии w.
При игре двух агентов равновесие Нэша (πi*, πj*) обеспечивается при следующем условии:
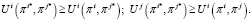 (25)
(25)
Для обеспечения равновесия агенты следуют стратегиям πi* и πj*. Отклонение от стратегий приводит к снижению полезности.
Выразим множество вероятностных векторов длины n через
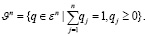 (26)
(26)
Для рассматриваемой игры существует по крайней мере одна смешанная стратегия, приводящая к равновесию Нэша, которая для стохастической игры может быть найдена путем решения задачи нелинейного программирования. Для стохастической игры из двух игроков получаем следующее выражение:
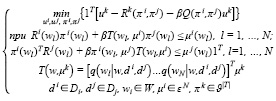 . (27)
. (27)
Глобальный минимум целевой функции определяет требуемые условия оптимальности, решение задачи нелинейного программирования (πi*, πj* ui*, uj*) будет формировать равновесие по Нэшу.
Методику анализа данных о ЧС и ее распространения в социальных сетях можно представить следующей последовательностью шагов:
Шаг 1 – Выбор социальной сети для анализа.
Шаг 2 – Выявление значимых кандидатов для оценки сообществ из пользователей сети.
Шаг 2.1 – Оценка репутации кандидатов по формулам (6) и (8).
Шаг 2.2 – Оценка интересности кандидатов по формулам (2) и (7).
Шаг 2.3 – Оценка личных познаний кандидатов по формулам (1), (3), (4), (5).
Шаг 2.4 – Нормализация показателей пользователей (10).
Шаг 2.5 – Ранжирование пользователей с помощью формулы (11).
Шаг 3 – Анализ сообществ по заданной тематике.
Шаг 3.1 – Поиск сообществ по их названиям в соответствии с ключевыми словами.
Шаг 3.2 – Оценка актуальности кандидатов по формулам (12) и (13).
Шаг 3.3 – Оценка интересности кандидатов по формулам (14) и (15).
Шаг 3.3 – Оценка репутации кандидатов по формулам (16) и (17).
Шаг 3.4 – Нормализация показателей сообществ с помощью формулы (19).
Шаг 3.5 – Ранжирование сообществ с помощью формулы (20).
Шаг 4 – Анализ данных по заданной тематике из выбранных сообществ.
Шаг 5 – Вывод результатов оператору в виде сообщений по заданной тематике, ранжированных по авторитетности пользователей.
Приведем пример использования предложенной методики. Допустим, в сети находится N = 1000 пользователей, коэффициент неопределенности λ = 0,5, исходные значения репутации ri выбраны случайным образом, коэффициент дисконтирования будущего вознаграждения β = 0,5.
В примере используем два типа пользователей: p1 – пользователь, пересылающий сообщения, основываясь на личной заинтересованности (p1+ – истинные сообщения, p1- – ложные сообщения), поэтому φ = τ = 0, ψ = 1; пользователь p2 (p2+ – истинные сообщения, p2- – ложные сообщения) имеет высокую репутацию, поэтому его коэффициенты будут равны φ = τ = 0,5, ψ = 0.
Используя формулу (11), получаем, что пользователи p1 будут распространять информацию с вероятностью s = 0,71, пользователи p2 с вероятностью s = 0,45. С помощью среды разработки PyCharm, языка программирования Python и библиотеки matplotlib построены кривые зависимости динамики распространения информации от параметров пользователей (рис. 1).
Из представленной диаграммы можно заметить, что ложные сообщения в начальной фазе быстро распространяются в широкие массы, но затем с течением времени их популярность падает. Это связано с тем, что после того, как в социальной сети появляется информация, например о ЧС, пользователи не сразу понимают, где истинные новости, но с течением времени получают подтверждение из других источников, и происходит отсеивание ложных сообщений.
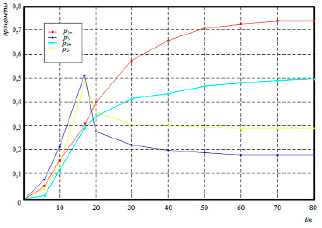
Рис. 1. Зависимости динамики распространения информации от параметров пользователей
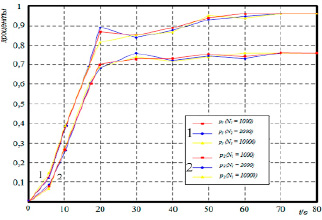
Рис. 2. Зависимость динамики распространения информации от размеров соцсети
Также из рис. 1 можно заметить, что пользователи, обладающие различными параметрами, имеют разный масштаб и скорость распространения их информации в социальной сети. Хотя распространение информации пользователями p1 быстрее, чем p2, это не означает, что пользователи p2 менее активные, а скорее это свидетельствует о том, что они делятся информацией с большей осторожностью.
В процессе исследования были сделаны выводы о том, что масштаб социальной сети практически не влияет на скорость распространения информации. На рис. 2 представлена динамика распространения информации в социальных сетях с численностью пользователей: N1 = 1000, N2 = 2000, N3 = 10000.
Также из рис. 2 можно выделить стадию стремительного распространения информации. Обладая достоверной информацией и имея авторитетный источник распространения, можно предотвратить популяризацию ложной информации на начальной стадии или снизить эффект ее воздействия на пользователей.
Заключение
Таким образом, в статье представлен процесс распространения информации по социальным сетям, выявлены параметры, влияющие на скорость ее популяризации, представлены два уровня анализа данных (уровень отдельных пользователей и уровень сообществ), представлена стохастическая игровая модель взаимодействия пользователей при обмене информацией, предложена новая методика, позволяющая анализировать информацию, опубликованную в социальных сетях о происходящих ЧС, с целью своевременного реагирования на них.
При разработке на основе представленной методики специализированного ПП появляется возможность мгновенного доступа к структурированной информации о происшествиях экстренным службам, что позволит сократить время реагирования на ЧС, а также своевременно предотвращать распространение ложной информации.