



Морфологический и синтаксический анализ естественного языка, как важные составляющие компьютерных лингвистических систем, необходимы для реализации механизма поиска, обслуживания национального корпуса языка, представления в качестве выходных данных морфологических и синтаксических составляющих текста (входной информации) [1–3].
В настоящей статье рассматриваются вопросы тестирования разработанного программного обеспечения национального корпуса чувашского языка, представляющего собой лингвопроцессор. На этапе проектирования морфологического и синтаксического анализатора выявлены характерные особенности чувашского языка, обработку которых необходимо реализовать в программном обеспечении (ПО) для корректности работы ПО [4]. Исходными целями разработки лингвопроцессора являются реализация морфологического анализа слов (соответствие лексико-грамматического класса), синтаксического анализа простых и сложных предложений чувашского языка [5, 6]. Морфологический анализатор национального корпуса чувашского языка реализован на основе теории, изложенной в [7, c. 83–87; 8, c. 120–123, и включает в себя следующие компоненты:
1. dll-библиотеку, содержащую морфологический анализатор и реализованную на языке C# с использованием платформы .NET Microsoft.
2. Вкладку «Морфологический анализатор» на сайте национального корпуса чувашского языка (http://yuman21.ru/Morf).
Вкладка «Морфологический анализатор» содержит следующие элементы пользовательского интерфейса:
1) текстовое поле для ввода анализируемого слова на чувашском языке с кнопками для ввода специальных чувашских символов (?, ?, ?, ç);
2) кнопку «Анализ», расположенную рядом c текстовым полем.
Морфологический анализатор, реализованный офлайн, содержит окно отображения результатов морфологического анализа как для отдельно введенного слова или фразы, так и возможность вставлять текст для анализа в специальном поле текствого ввода.
База данных морфологического анализатора состоит из словаря основ чувашского языка и базы аффиксов.
Словарь представляет собой текстовый файл, в котором слова представлены следующим образом: слово, часть речи, информация об источнике. В нем собрано более тридцати одной тысячи слов чувашского языка.
Процесс морфологического анализа разделен на два этапа. На первом этапе слово в исходной форме ищется в словаре основ. Грамматические характеристики в данном случае определяются по умолчанию в зависимости от части речи. На втором этапе производится непосредственный анализ слова, разбиение его на пары «корень-аффиксы» и извлечение характеристик. Оба этапа возвращают произвольное количество омонимов в зависимости от найденных совпадений. При отсутствии совпадений слово возвращается с «неопределенными» характеристиками.
Прямой поиск входного слова в словаре основ выполняет функция SearchInDictionaries.
Второй этап реализован в функции DetermineOnYourOwn. Исходное слово подвергается пошаговому разбиению на аффиксы и происходит исследование на основе выделения его компонент (основы и аффиксов) на предмет принадлежности к какой-либо части речи.
Основной задачей синтаксического блока лингвистического процессора (ЛП) является преобразование морфологической структуры (МорфС) предложения, поступающей с выхода морфологического блока, в синтаксическую структуру (СинтС). Синтаксический анализатор национального корпуса чувашского языка реализован на основе теории, изложенной в [9, c. 91–99]. Так как МорфС предложения состоит из МорфС отдельных словоформ, то переход от МорфС предложения к его СинтС осуществляется путем установления синтаксических связей между МорфС слов и между самими связями. При этом МорфС отдельных словоформ служат для установления этих связей или, как принято их называть в компьютерной лингвистике, отношений. Поэтому от того, какую модель данных для представления СинтС мы примем за основу, будет зависеть эффективность работы синтаксического блока ЛП. Структура синтаксического анализатора состоит из следующих 10 классов:
SyntParser.cs – основной класс. Содержит поля и методы для работы с библиотекой.
1. MainWork.cs – класс, который отвечает за определение характеристик предложения.
2. AttributesDeterminer.cs – класс, который предоставляет основные методы по анализу предложений. Объединяет все полученные данные под одним объектом.
3. AttrDeterHelper.cs – вспомогательный класс класса AttributesDeterminer.
4. Combinator.cs – класс, который на основе входного предложения формирует всевозможные вариации предложения.
5. Helper.cs – класс, в котором собраны общие вспомогательные функции.
6. BorderingWork.cs – класс, который отвечает за определение границ простых предложений в сложном.
7. Relations.cs – класс, отвечающий за определение отношений (связей) между словами.
8. GraphMaker.cs – класс, который формирует граф на основе выявленных отношений.
9. SyntConstants.cs – класс синтактических констант, используемых в проекте.
Разработанная библиотека выполняет следующие действия:
1. Определение подлежащих и сказуемых предложения.
2. Определение границ простых предложений.
3. Определение связей между словосочетаниями.
4. Визуализация выявленных связей.
5. Возможность вывода результатов в файл.
6. Режим логгирования для удобной отладки.
Определение корректности и соответствия результатов исходным данным возможно при комплексном тестировании программного обеспечения с использованием форм с характерными особенностями и исключениями в качестве входной информации [10].
Комплексное тестирование необходимо для нахождения несоответствий системы ее исходным целям. Разработанное ПО, благодаря дружественному интерфейсу, позволяет даже неопытному пользователю быстро разобраться в принципе работы системы. Главные пункты тестирования:
1. Корректность морфологического и синтаксического анализа.
2. Быстродействие программы.
Для контроля корректности анализа на вход приложения поступили слова с несколькими значениями, слова-исключения, слова с максимальным количеством букв и т.д. Далее приводятся основные направления тестирования на конкретных примерах, в статье они обозначены отдельными пунктами, результаты приведены на рисунках и в таблицах.
1. Слово «çур?» верно распознано. Лингвопроцессор вернул все три значения слова. Существительное «çур + ?» (его сруб), глагол в будущем времени «çур+?» (порубит), глагол в прошлом времени «çу + р + ?» (помыл). Морфологические характеристики также отмечены верно (рис. 1). В программе реализовано представление нескольких значений слова, доступ к которым пользователь получает при помощи переключателя, на рис. 1 переключатель активировал позицию «1/3», данная позиция соответствует первому значению слова, последующие два значения слова определены системой корректно. Основные результаты тестирования сведены в табл. 1, в скобках указаны значения слов.
Таблица 1
Результаты тестирования морфологического анализатора
|
Слово |
Часть речи |
Корень |
Аффиксы |
Падеж |
Время |
Число |
Лицо |
|
çур? (его сруб) |
имя существительное |
çур |
? |
основной |
– |
единственное |
3е |
|
çур? (порубит) |
глагол |
çур |
? |
– |
будущее |
единственное |
3е |
|
çур? (помыл) |
глагол |
çу |
р | ? |
– |
прошлое |
единственное |
3е |
|
велосипедлисемпехч?-и? (был с велосипедными же) |
прилагательное |
велосипед |
ли | сем |пе |х| ч? | -и |
творительный |
прошлое |
множественное |
– |
|
сур?м |
имя существительное |
сур? |
м |
основной |
– |
единственное |
1е |
|
сур?м |
глагол |
су |
р | ?м |
– |
прошлое |
единственное |
1е |
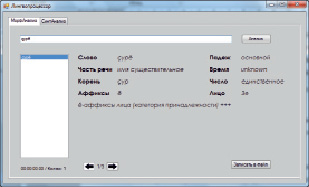
Рис. 1. Окно результатов анализа слова
2. Слово «велосипедлисемпехч?» (был с велосипедными же) с шестью аффиксами протестировано корректно. Грамматические характеристики определены правильно, включая описание аффиксов (табл. 1).
3. Анализ слова «сур?м» также верно дал результаты: существительное «сур? + м» и глагол в прошлом времени «су + р + ?м».
Быстродействие оценивается средствами самого языка программирования C#. Класс Stopwatch предоставляет набор функций и свойств, которые можно использовать для точного измерения затраченного времени. Необходимо точно измерить время потраченное на анализ одного слова, нескольких слов, большого текста. В случае с синтаксическим анализатором интересует скорость анализа предложения простого и сложного [11].
В результате тестирования сделаны следующие выводы. Слова с максимальным количеством букв обрабатываются не более чем за 3 миллисекунды. 10 слов с разным количеством букв в среднем обрабатываются лингвопроцессором менее чем за 7 миллисекунд (рис. 2). Результаты анализа 100 слов с различным количеством букв следующие: система произвела анализ за 36 миллисекунд (рис. 3).
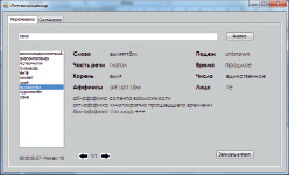
Рис. 2. Окно результатов анализа десяти слов
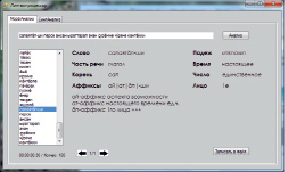
Рис. 3. Окно результатов анализа ста слов
4. Анализ простого предложения «Ачасем паян шкула каяймар?ç!» завершился за 4 миллисекунды. Полученные результаты оказались корректными: типы, главные члены определены верно, граф сформировался согласно полученным связям.
5. Анализ сложного предложения. Выявлены все простые предложения, тип установлен верно, граф сформирован корректно. Время работы со сложным предложением практически не отличается от анализа простого: 3 миллисекунды (рис. 4). Результаты тестирования простых и сложных предложений сведены в табл. 2.
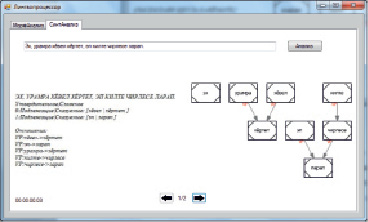
Рис. 4. Окно результатов анализа сложного предложения
Таблица 2
Результаты тестирования синтаксического анализатора
|
Предложение |
Тип предложения, Подлежащее|Сказуемое |
Отношения |
|
Ачасем паян шкула каяймар?ç! |
Восклицательное, простое 0:Подлежащее|Сказуемое: [ачасем|каяймар?ç] |
VP: ачасем -> каяймар?ç VP: паян -> каяймар?ç VP: шкула -> каяймар?ç |
|
Эх! Урамра х?вел х?ртет, эп килте чирлесе ларап |
Утвердительное, сложное 0:Подлежащее|Сказуемое: [х?вел | х?ртет] 1:Подлежащее|Сказуемое: [эп | ларап] |
VP: х?вел -> х?ртет VP: эп -> ларап VP: урамра -> х?ртет VP: килте -> чирлесе VP: чирлесе -> ларап |
Таблица 3
Результаты тестирования быстродействия системы
|
Входная информация |
Значение |
Результаты |
|
Слово с минимальным количеством букв |
ача |
1 миллисекунда |
|
Слово с максимальным количеством букв |
велосипедлисемпехч? |
3 миллисекунды |
|
10 слов |
10 слов разной длины |
7 миллисекунд |
|
100 слов |
100 слов разной длины |
36 миллисекунд |
|
Простое предложение |
Ачасем паян шкула каяймар?ç! |
4 миллисекунды |
|
Сложное предложение |
Эх! Урамра х?вел х?ртет, эп килте чирлесе ларап. |
3 миллисекунды |
Во время тестирования никаких программных ошибок не выявлено. Нажатие по кнопке «Анализ» при пустой строке входных данных не выкидывает исключений. Кнопка «Записать в файл» доступна только при наличии слов в левой колонке. Изображения всех вариаций графов и информации о предложении успешно создавались и отображались. Результаты тестирования системы на быстродействие сведены в табл. 3. Как видно из таблицы, время работы с простым или сложным предложением не превышает 3–4 миллисекунд.
В качестве эксперимента выбирались слова и предложения из разных открытых источников, размещенных на сайте национального корпуса чувашского языка. Во всех случаях при наличии морфем в словаре программа производила точный анализ с правильным определением всех атрибутов, отсутствие морфем при экспериментах не обнаружено.
Исследование выполнено при финансовой поддержке РФФИ в рамках научного проекта № 15-04-00532.
Библиографическая ссылка
Желтов В.П., Желтов П.В., Сергеев Е.С. РЕЗУЛЬТАТЫ ТЕСТИРОВАНИЯ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ НАЦИОНАЛЬНОГО КОРПУСА ЧУВАШСКОГО ЯЗЫКА // Современные наукоемкие технологии. – 2017. – № 8. – С. 13-18;URL: https://top-technologies.ru/ru/article/view?id=36772 (дата обращения: 19.04.2024).